 利用Calibre RVE高效筛选大型DRC结果数据库
利用Calibre RVE高效筛选大型DRC结果数据库

您是否有过这样的经历,为了完成一个错误较多的大型芯片级设计上运行的设计规则检查 (DRC),您苦等了几个小时,结果发现得到的 DRC 结果数据库 (RDB) 文件大小竟然达到数百GB,其中更有数百万条需要审查的错误结果,然后,您还需要编辑设计,使其符合晶圆代工厂的设计规则要求?在传统的调试流程中,审查大量 DRC RDB 可能是一个非常耗时的阶段,这主要是因为与这些大型数据集相关的加载、筛选和显示时间过长。即使应用定制筛选器或使用豁免来减少必须调试的结果数量,要加载整个 RDB 并处理每个结果,所需的时间也会耗费掉大部分的任务时间。
现在,您终于有了更好的选择。工程师可以将这些巨大的 RDB 划分为更小的 RDB,然后再将它们加载到结果查看器中,仅仅选择和加载那些需要立即关注的高优先级问题的结果,从而避免加载完整 RDB 所造成的性能损失。
1传统筛选
不过,让我们首先来看看筛选大型 RDB 的现有方法,通过 Calibre RVE 结果可视化环境来演示这些方法的使用过程。工程师可以利用 Calibre RVE 界面加载 RDB,然后在其设计工具中直观地检查和分析错误标记(图 1)。
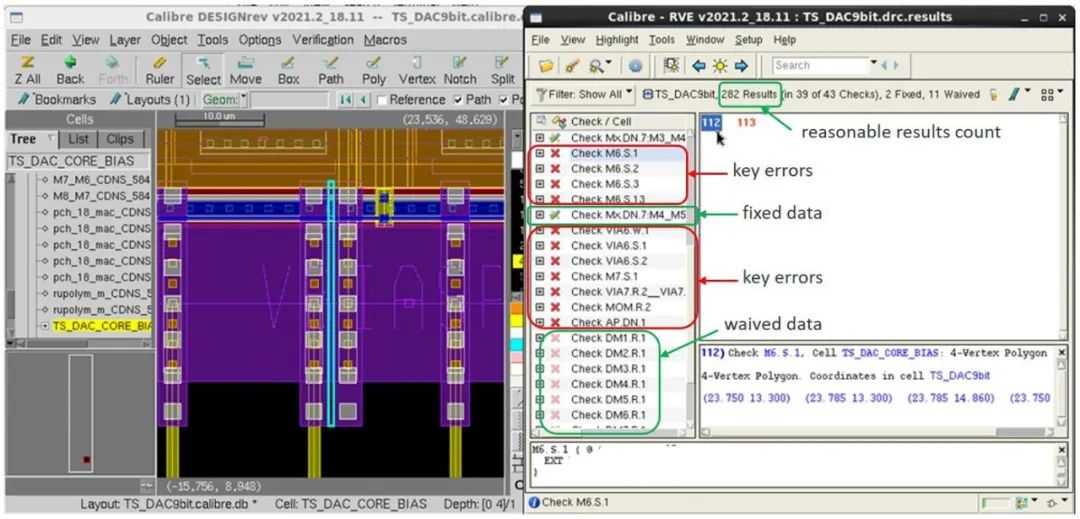
图 1. 与 Calibre DESIGNrev 芯片完工修整平台集成的
Calibre RVE 结果显示
定制筛选器
工程师通常通过将结果筛选成组来管理大型 RDB,这样他们就能集中精力,一次处理一组结果。我们的目标是查看检查名称与 “M1*” 匹配的结果。在我们的示例中,我们将使用一个 110GB 的 Calibre nmDRC RDB,其中包含 1.2G 的结果。Calibre RVE 界面需要 25 分钟来加载此 RDB 文件并在 Calibre DESIGNrev 界面显示结果。
Calibre RVE 提供了一个直观的筛选器编辑器,供工程师创建定制筛选器。然后,他们可以将这些定制筛选器应用于 RDB,仅显示与给定标准匹配的错误(图 2)。定制筛选器可以保存并用于多个 RDB,因而成为一种非常有效的解决方案,专门处理设计团队日常感兴趣的错误类型。
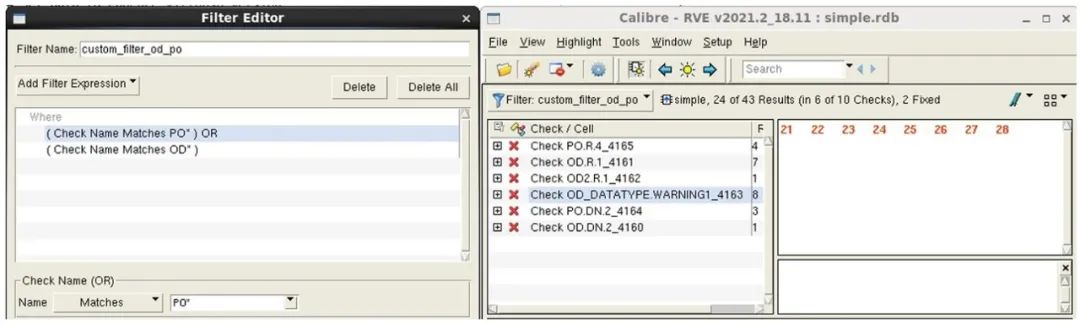
图 2. 具有定制筛选器的 Calibre RVE
但是,Calibre RVE 仍须加载 RDB 并在内存中处理每个结果,才能创建经筛选的结果。因此,这种方法适合中小型 RDB,而对于像我们示例所示的大型 RDB,仍可能需要大量的时间。
此外,筛选器编辑器仅适合创建采用树结构的简单筛选器。工程师如果需要更复杂的筛选器,可能会发现此解决方案不够用。
豁免
另一个选项允许工程师筛掉允许的(被豁免的)违规,以便他们可以专注于确实必须调试的结果。工程师使用晶圆代工厂 Calibre PDK 团队和 / 或 CAD 团队提供的 DRC 前期豁免文件执行 Calibre nmDRC 运行,以生成包含豁免和未豁免结果的 RDB。
然后,工程师可以在 Calibre RVE 中将内置的 “显示未豁免” 筛选器应用于此 RDB,使其仅仅关注未豁免的错误(图 3)。与定制筛选器方法一样,豁免方法适用于中小型 RDB,但不适用于大型 RDB。Calibre RVE 仍须加载并处理整个 RDB,然后才能筛选并且仅显示未豁免的结果。
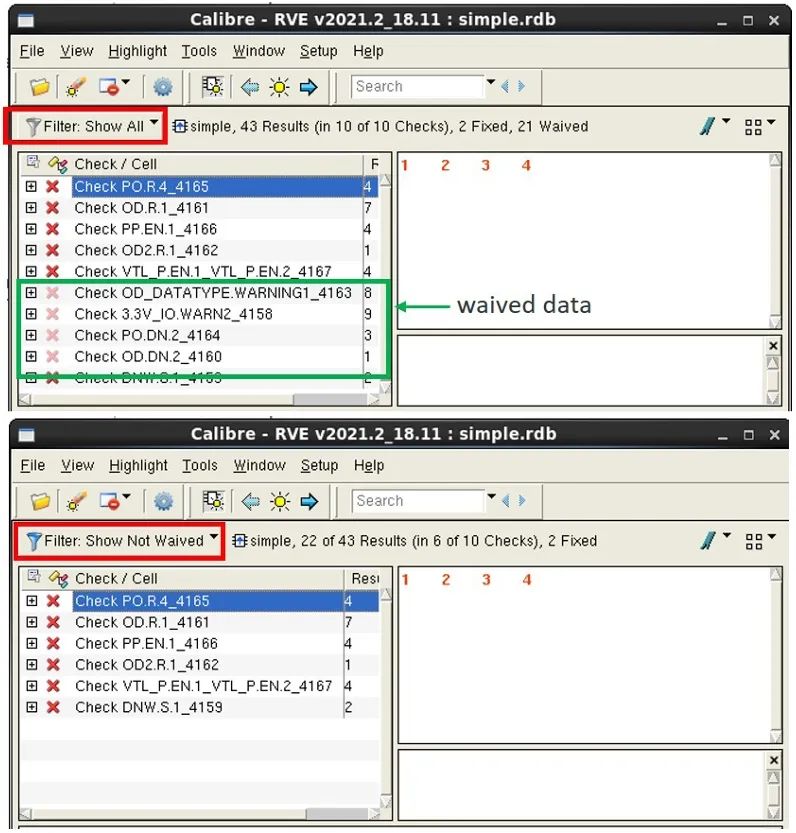
图 3. Calibre nmDRC 豁免方法
使用定制筛选器的豁免
结果筛选功能最常见的用途是结合定制筛选器和豁免(图 4),以便仅显示对修复设计至关重要的关键错误(图 5)。如您所料,这种方法虽然从结果筛选的角度来看非常有用,但非常耗时。
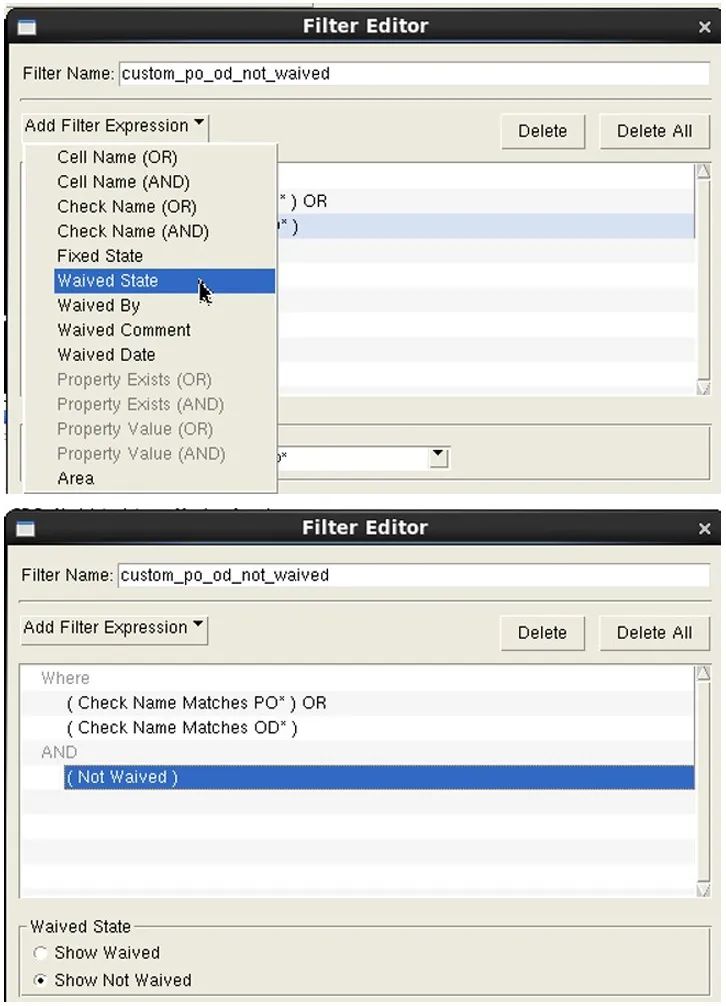
图 4. 将筛选器编辑器的定制筛选器与豁免相结合
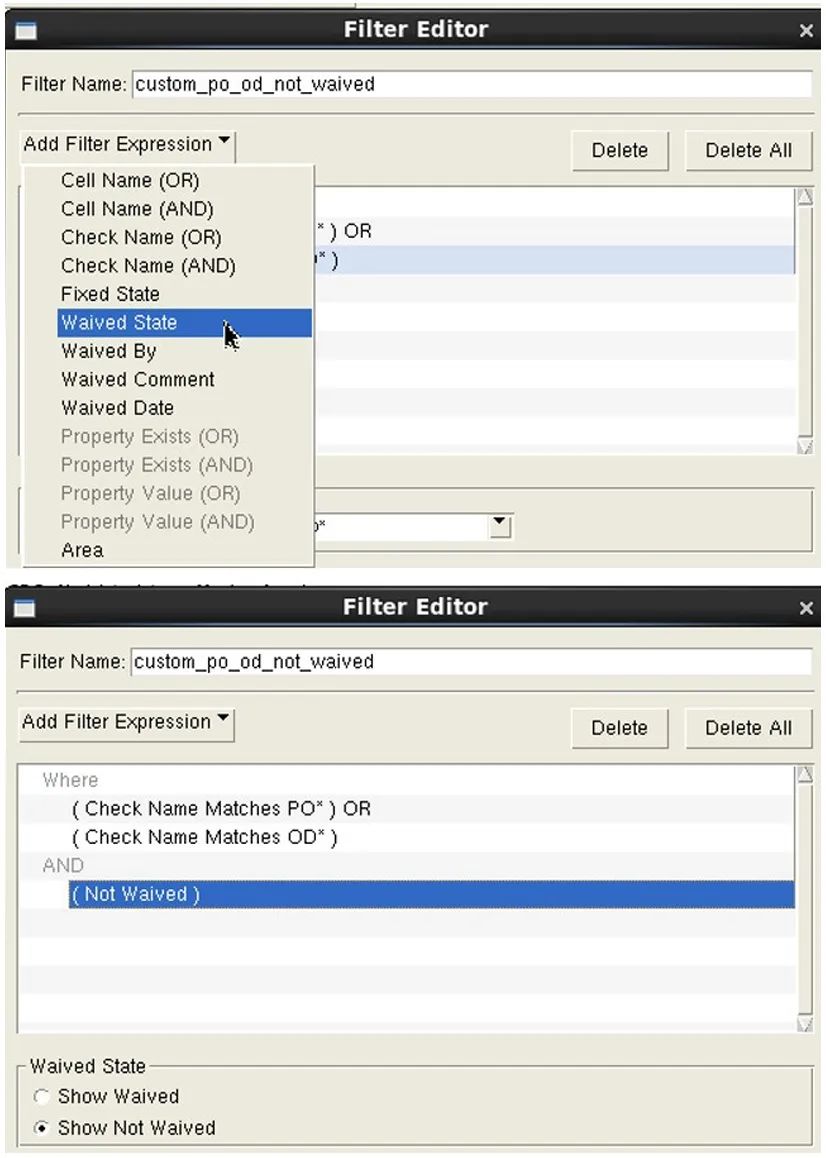
图 5. 将定制筛选器与豁免相结合,
提供一组定向的需要修复的严重错误结果
鉴于上述现有方法的局限性,设计和验证团队需要一种选项,让他们能够在更短的时间内使用更少的内存资源来筛选非常大的 RDB。
2批量筛选
批量筛选是一种创新技术,工程师可利用该技术在 RDB 上应用筛选器表达式,并使用批处理 Calibre RVE 运行创建更小的 RDB——换言之,无需将完整的 RDB 加载到内存中。筛选器表达式使用与定制筛选器方法相同的筛选器编辑器表达式关键字,而 Calibre RVE 则将这些筛选器表达式用作命令行参数。利用这种方法,设计人员可以开发他们的定制筛选器表达式,并通过共享他们的 Calibre RVE 命令和参数轻松地与其他设计人员分享:
calibre -rve -drc
让我们来看几个示例,以展示批量筛选器流程是如何工作的。我们从原始 RDB 文件开始(图 6)。
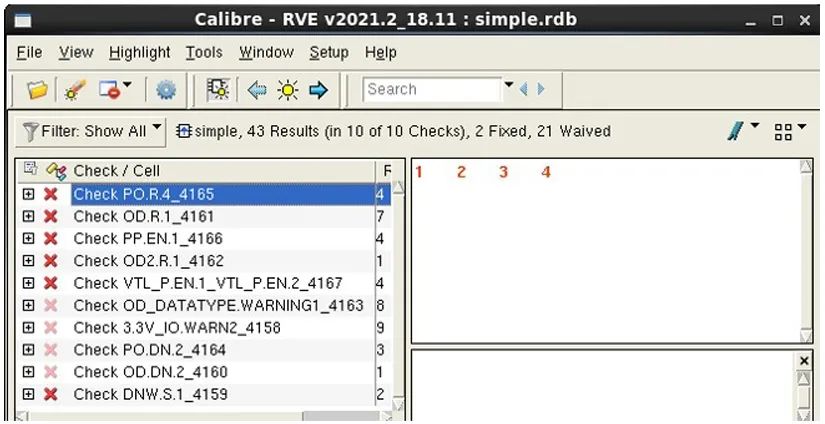
图 6. 原始 RDB 文件
在我们的第一个示例中,我们创建了一个 RDB 文件,其中仅包含检查名称带有 “OD” 或 “PO” 前缀的错误。我们为批处理 Calibre RVE 命令设置了一条筛选器约束,创建一个新的 RDB 文件 “od_po.rdb”,其中仅包含带有前缀 “OD” 和 “PO” 的检查名称。
calibre -rve -drc simple.rdb -filter -check “OD* PO*” -output od_po.rdb
图 7 显示了相应结果。由批处理运行创建的经筛选的 RDB 中包含 24 个错误结果。
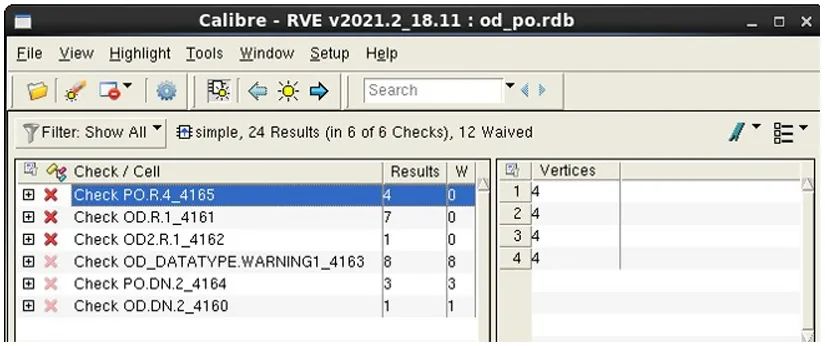
图 7. RVE 批量筛选结果仅包含 OD* 和 PO* 检查
在这些结果中,我们注意到,有 12 个豁免的结果。在我们的示例中,让我们更进一步,创建一个 RDB 文件,其中仅包含带有前缀 “OD” 或 “PO” 的检查名称的错误,并排除所有豁免的结果。现在,我们的批处理 Calibre RVE 命令运用筛选器约束创建了一个新的 RDB 文件 “rve_filter.rdb”,其中仅包含带有前缀 “OD” 和 “PO” 的检查名称,并从文件中清除了所有豁免的结果。
calibre -rve -drc simple.rdb -filter -check “OD* PO*” -unwaived -output rve_filter.rdb
如图 8 所示,结果计数现在显示没有豁免的结果。这个经筛选的 RDB 中包含 12 个未豁免的结果。
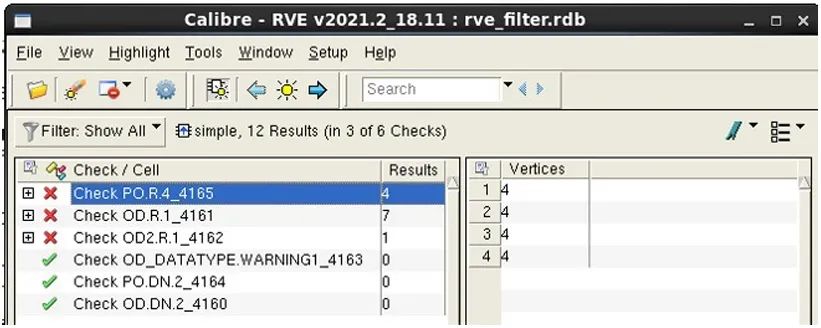
图 8. 不含豁免结果的 RVE 筛选器结果
在下一个示例中,我们想要创建一个 RDB 文件,其中仅包含特定直线边区域中的错误,而将其余结果放在另一个 RDB 中。以下批处理 Calibre RVE 命令运用筛选器约束创建一个 RDB 文件 “area.filter.rdb”,其中仅包含指定区域的结果,并创建另一个 RDB 文件 “other.filter.rdb”,其中包含剩余的结果。
calibre -rve -drc simple.rdb -split -filter -include_area “simple - 76.700 233.700 38.500 233.700 38.500 120.800 -8.400 120.800 -8.400 174.900 -76.700 174.900” -output area. filter.rdb -filter -other -output other.filter.rdb
图 9 显示了此批量筛选器运行创建的两个 RDB。
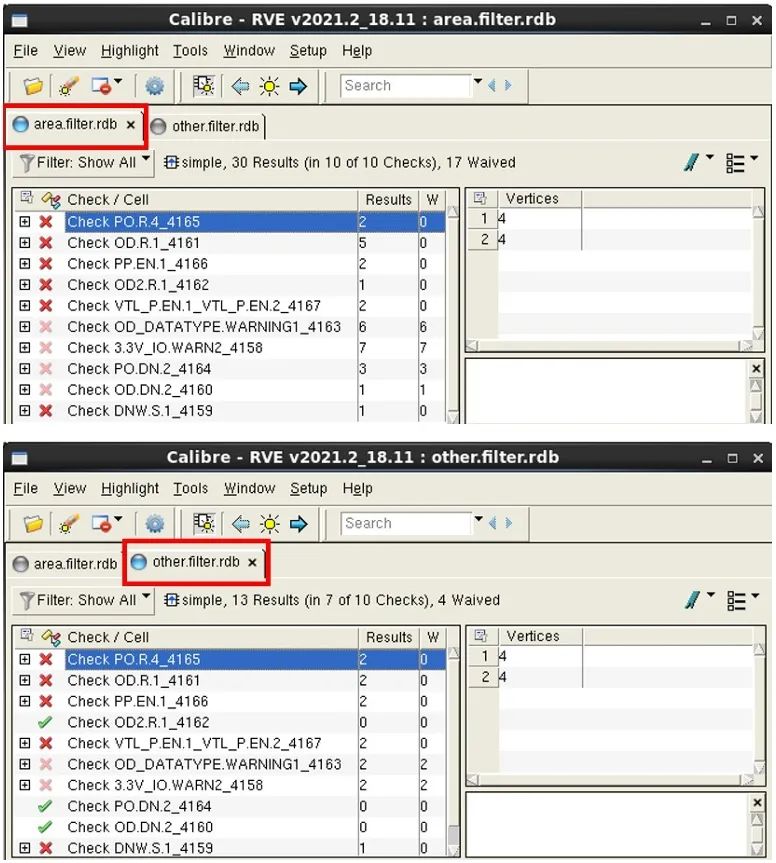
图 9. 在多个 RDB 文件之间
拆分 RVE 批量筛选结果
在下一个示例中,让我们来看看批量筛选器过程如何处理更复杂的筛选条件。我们将使用筛选器,通过检查名称和属性范围的布尔组合创建一个 RDB。以下批处理 Calibre RVE 命令运用筛选器约束创建了一个 RDB “boolean.rdb”,其中包含检查名称 “default” 且属性 “CD” 的值大于 200、小于 250 的结果,以及检查名称 “short_ports” 且属性 “CD” 的值大于 250、小于 300 的结果。
calibre -rve -drc input.rdb -filter -check “default” -property “200 < CD < 250” -OR -check “short_ports” -property “250 < CD < 300” -output boolean.rdb
图 10 显示了批量筛选器创建的 RDB。其中仅包含符合指定标准的结果。
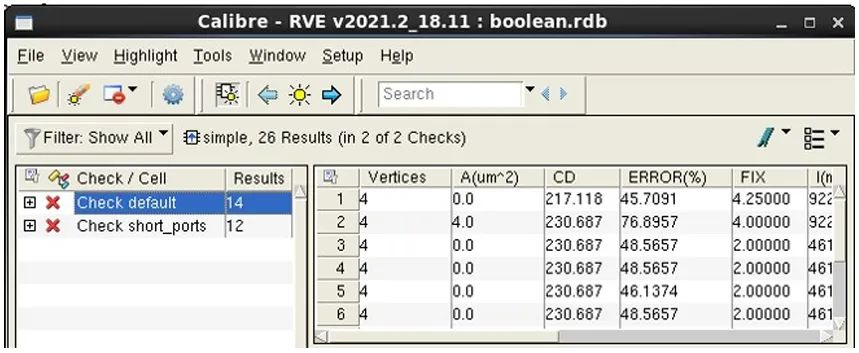
图 10. CD 属性在某个范围内的
RVE 批量筛选结果
3性能比较
为了将传统筛选器技术与批量筛选器过程的性能进行比较,我们使用批量筛选器过程将定制筛选器应用于我们的 110GB RDB,以创建 RDB “m1.rdb”,其中包含前缀为 “M1i” 的检查名称的结果,以及 RDB “m2.rdb”,其中包含前缀为 “M2i” 的检查名称的结果。
calibre -rve -drc 110GB.rdb -split -filter -check “M1i*” -output m1.rdb -filter -check “M2i*” -output m2.rdb
表 1 显示了相应结果。

表 1:批处理 RVE 筛选运行汇总
然后,我们比较了加载 RDB 文件并应用内置筛选器以删除豁免结果所需的运行时间性能和内存使用量。
表 2 显示了相应结果。

表 2:加载 RDB 文件并应用内置筛选器所用的时间
使用传统方法,Calibre RVE 界面需要 25 分钟加载原始 RDB,使用了 77.7GB 内存。然后需要一个小时将 “显示未豁免” 筛选器应用于结果。
使用批量筛选过程,Calibre RVE 需要 47 分钟创建两个较小的 RDB。然后需要 14 秒钟加载第一个 RDB,内存使用量为 1.5GB,需要 6 分钟加载第二个 RDB,使用了 10.5GB 内存。加载后,第一个 RDB 用了 2 秒钟的筛选时间删除豁免的结果,而第二个 RDB 则需要 18 秒钟。整个过程的总时间不到一小时,总内存使用量为 12GB。
找到有效的方法来筛选结果数据,对于优化结果调试时间和资源使用量有着重要的意义。虽然设计团队在 Calibre nmDRC 运行期间可以生成经筛选的较小 RDB 文件,但它需要修改晶圆代工厂的规则集,而这通常是不可取的。此外,加载时间耗费了总体运行时间的很大一部分,而且使用了大量的内存资源。在图形界面应用程序中快速加载较小的数据库时可以利用内置的筛选器,但更大的数据库可能会影响计划和资源。
当处理千兆级数据库时,设计团队可以利用 Calibre RVE 批量筛选过程等外部筛选操作,以节省大量时间和资源,并创建更高效的调试流程。设计人员可以利用 Calibre RVE 批量筛选过程将筛选表达式应用于 RDB,以更少的内存将匹配的结果写入到更小的输出文件。设计团队可以在任何文本编辑器中创建定制筛选器,然后轻松地对其他 RDB 文件重复使用这些筛选器,以及与团队成员或其他团队分享筛选器。通过更快地创建较小的定向 RDB,设计团队可以集中他们的时间和资源,更快、更高效地调试关键错误,从而改善结果,同时缩短流片时间。
-
芯片
+关注
关注
460文章
52624浏览量
442777 -
数据库
+关注
关注
7文章
3941浏览量
66598 -
DRC
+关注
关注
2文章
155浏览量
37227 -
编辑器
+关注
关注
1文章
823浏览量
32131
原文标题:批量筛选器:更好更快地筛选大型 DRC 结果数据库
文章出处:【微信号:Mentor明导,微信公众号:西门子EDA】欢迎添加关注!文章转载请注明出处。
发布评论请先 登录
《电子发烧友电子设计周报》聚焦硬科技领域核心价值 第17期:2025.06.23--2025.06.27
《Visual C# 2008程序设计经典案例设计与实现》---利用水晶报表筛选数据库中的数据
labview根据时间筛选数据库的内容
calibre跑完后调不出RVE视窗的问题该如何去解决?
怎样去改用calibre过DRC时的错误?
大型无缝影像数据库管理系统的设计与实现
大型数据库实验指导
一个大规模分布式原生XML数据库原型系统





 工商网监
工商网监
评论