 DeepSeek R1 MTP在TensorRT-LLM中的实现与优化
DeepSeek R1 MTP在TensorRT-LLM中的实现与优化

TensorRT-LLM 在 NVIDIA Blackwell GPU 上创下了 DeepSeek-R1 推理性能的世界纪录,Multi-Token Prediction (MTP) 实现了大幅提速。我们在之前的博客[1]中介绍了 DeepSeek-R1 模型实现超低推理延迟的关键优化措施。本文将深入探讨 TensorRT-LLM 中的 MTP 实现与优化。
MTP 在推理中的应用
受先前研究工作的启发,MTP 用于辅助 DeepSeek-V3 的训练,在主模型末尾添加额外的 MTP 模块,并使用这些模块预测更多 token。这可以将 MTP 的预测范围扩展到每个位置的多个候选 token,从而提高模型准确性。这些 MTP 模块还可用于推理过程中的投机采样,以此进一步降低生成延迟。本章将介绍适用于 LLM 推理的 MTP 投机采样算法。
背景
投机采样是一种提高 LLM 推理速度和成本效益的主流技术,其基本原理是生成多个候选 token,与处理单个 token 相比能更加高效地利用 GPU,特别是在计算需求较低的解码阶段。投机采样技术通常将此过程分为低成本的 draft 阶段和并行验证阶段。Draft 阶段使用小模型或主模型的一部分层预测候选 token。验证阶段则使用主模型确定接受多少个候选 token,这比每次迭代生成一个 token 高效得多。

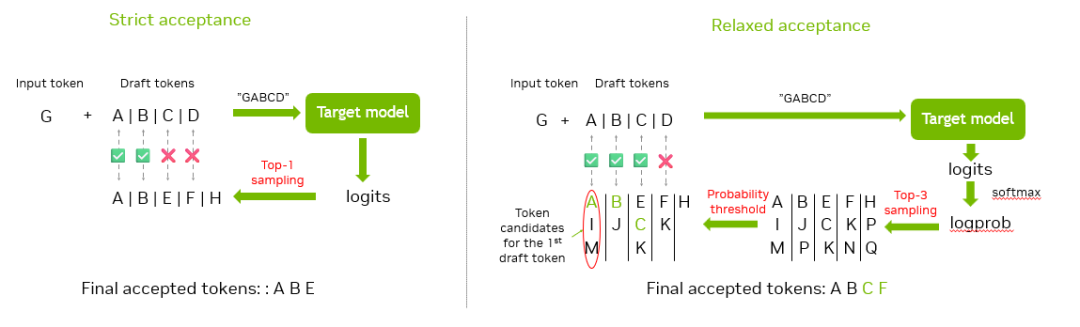
图 1. 验证示例
图 1 是一个有关如何验证并接受这些候选 token 的示例。假设共有 5 个候选 token “ABCDE”,我们将它们拼接到输入 token “G”,并向主模型输入总共 6 个 token。采样后,我们可以得到 6 个不同的预期 token,然后将预期 token 与候选 token 进行比较,并接受最长的前缀匹配 token。此示例中匹配的 token 是 “ABC”。由于 “H” 由主模型预测,且对应的输入 token “C” 已被接受,因此 “H” 也将被接受。这样一来,我们可以在单次迭代中接受四个 token。MTP 也使用此方法验证并接受候选 token。在 MTP 的 draft 阶段有两种 MTP 方法:MTP Vanilla 和 MTP Eagle。它们适用于不同的推理场景。
MTP Vanilla
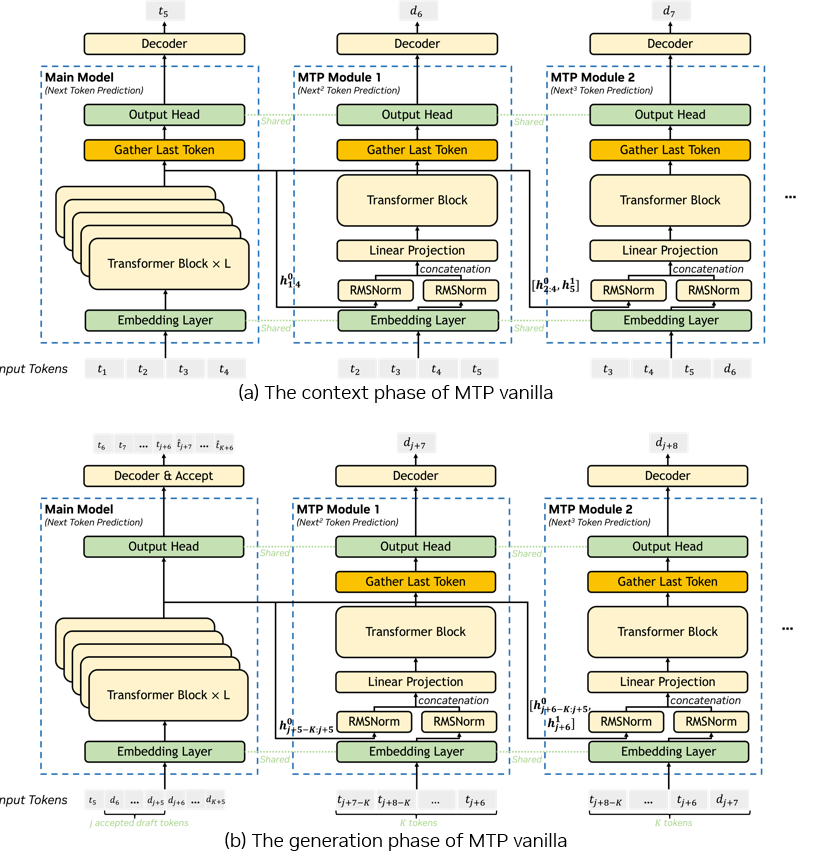
图2. MTP Vanilla,其中ti为输入token,di为预测的候选token,K为MTP模块数量,hin为第n个MTP模块的隐藏状态。需注意h0表示主模型的隐藏状态。
(注:图改编自DeepSeek V3技术报告https://arxiv.org/pdf/2412.19437)
MTP Vanilla 方法与 MTP 训练更为相似,该方法按序调用不同 MTP 模块来预测多个候选 token,支持包含多个不同 MTP 模块权重的模型 checkpoint,且每个 MTP 模块均拥有独立的 KV 缓存。
图2是MTP Vanilla的推理流程。在预填充阶段,假设总共有四个输入token,我们将在主模型前向传播后获得输出tokent5和隐藏状态。输出token将附加到输入token上,然后移除第一个token,得到t2到t5作为第一个MTP模块的输入token。主模型的隐藏状态将直接作为第一个MTP模块的输入,用于预测第一个候选token。对于接下来的几个MTP模块,我们将新生成的候选token与对应最后一个输入token的隐藏状态附加到输入token和隐藏状态中。然后,我们将移除第一个token以准备下一个MTP模块的输入。通过这种方式,我们可以尽可能多地保留主模型中的信息,有助于MTP模块做出更准确的预测。
在生成阶段会有一点差异。预测的tokent5和候选token将作为主模型的输入。在主模型前向传播后,我们将进行验证以获取被接受的token。此示例假设j个候选tokend6~$d_{j+5}$被接受,然后准备MTP模块的输入与预填充阶段不同,我们将此前所有接收token中的最后K个token及其对应的隐藏状态作为第一个MTP模块的输入,该示例中最后一个被接受的token是t_{j+6},则输入为t_{j+7-K}~t_{j+6},然后我们可以获得第一次MTP模块前向传播后的第一个候选token。对于后续的MTP模块,我们可通过与预填充阶段中的MTP模块类似的方式准备它们的输入,所有这些MTP模块都具有相同的输入序列长度。在预测完所有新的候选token后,由于验证阶段很多token没有被接收,需要将这些被舍弃的候选token的键/值从模型的KV缓存中清除,以确保后续计算的正确性。
MTP Eagle
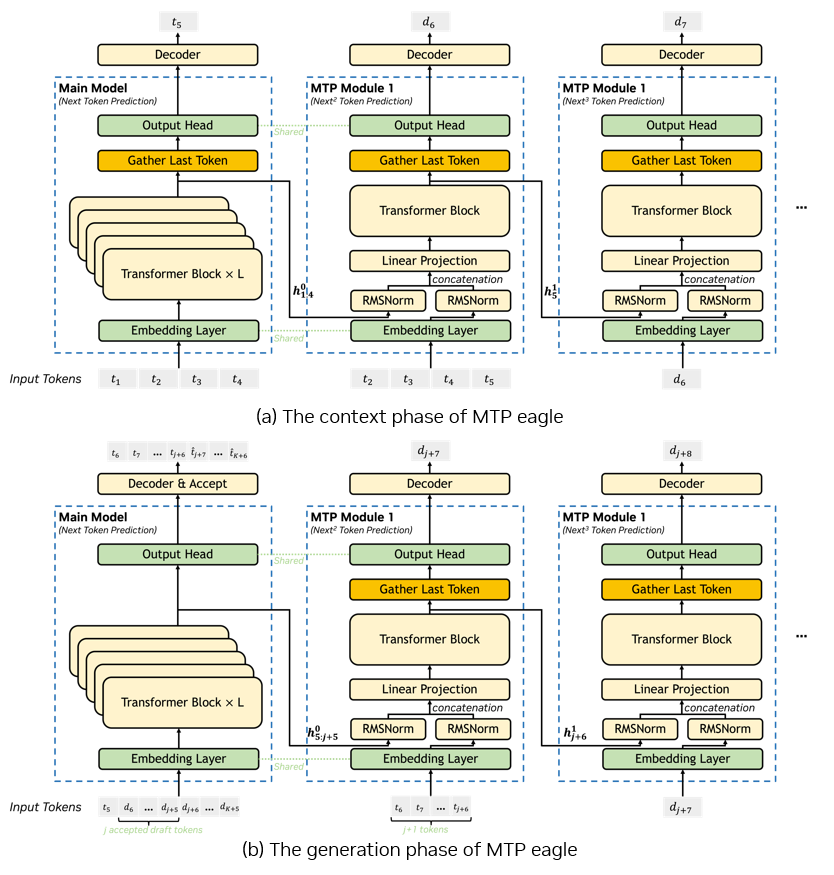
图 3. 使用与图 2 相同标记的 MTP Eagle
(注:图改编自 DeepSeek V3 技术报告 https://arxiv.org/pdf/2412.19437)
MTP Eagle 可以被视为 Eagle 投机采样方法的变体,但目前仅支持链式解码。该方法复用同一个 MTP 模块并重复多次来预测候选 token,因此 MTP Eagle 用于支持仅包含 1 个 MTP 模块的模型 checkpoint,官方 DeepSeek-V3 和 DeepSeek-R1 的checkpoint 中仅包含 1 个 MTP 模块,适用于 MTP Eagle。其与 MTP Vanilla 的另一个差异在于 KV 缓存,MTP Eagle 方法中的 MTP 模块在预测多个候选 Token 时复用相同的 KV 缓存。
图 3 是一个 MTP Eagle 示例。在预填充阶段,第一个 MTP 模块的输入与 MTP Vanilla 相同,但是在后续 MTP 模块前向传播过程中有些不同,首先 MTP Eagle 使用相同的 MTP 模块预测候选 token 并复用相同的 KV 缓存,其次我们只需输入 1 个 token 的 token ID 和其隐藏状态,该 token 是前一个 MTP 模块预测得到的候选 token。通过这种方式,我们只使用 1 个 MTP 模块就可以预测总共 K 个候选 token。
生成阶段的验证过程与 MTP Vanilla 类似。在获得接受的 token 后,我们将所有被接收的 token 及其对应的隐藏状态作为第一个 MTP 模块前向传播的输入,与需要存储过去 token 和隐藏状态的 MTP Vanilla 不同,这种方法实现起来要简单得多。后续 MTP 模块前向传播采用与预填充阶段相同的方法来准备输入。在预测所有候选 token 后,与 MTP Vanilla 类似,需要清除模型 KV 缓存中所有被舍弃 token 的键 / 值。
TensorRT-LLM 中的 MTP 实现方式
基本实现方式
TensorRT-LLM 提供了两条不同的 MTP 实现路径,一条对应 MTP Vanilla,另一条对应 MTP Eagle。MTP Eagle 是 DeepSeek-V3 和 DeepSeek-R1 模型的默认路径。
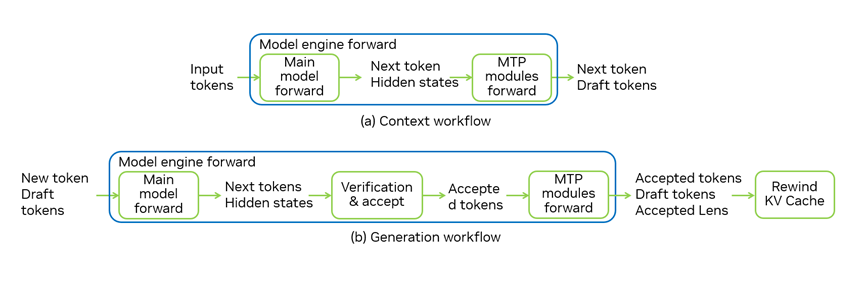
图 4. TensorRT-LLM 中的 MTP 工作流
图 4 是 TensorRT-LLM 中的完整 MTP 工作流。两条路径共用同一运行时工作流,差别则在于 MTP 模块的前向传播。在预填充阶段,输入中不包含候选 token,TensorRT-LLM 模型引擎从请求中获取输入 ID,并将其输入到模型引擎进行前向传播以获取下一个 token 和隐藏状态。随后准备 MTP 模块输入,MTP 模块通过前向传播来预测候选 token。
生成工作流更为复杂,需要同时进行验证和预测候选 token,预测的新 token 和候选 token 为主模型的输入。在主模型前向传播后,我们可以从输出的 logits 中采样并获取新的 token,然后将它们与输入的候选 token 进行比较,以获取最终接受的 token 来完成对候选 token 的验证。我们将使用接受的 token 和隐藏状态启动一个新的 draft 阶段,该阶段使用 MTP 层预测下一轮迭代的新候选 token。最后,我们需要回滚 KV 缓存以清除与被拒绝 token 对应的键值对。
除了回滚 KV 缓存外,所有这些过程均在模型引擎前向传播中完成。这样我们可以使用一个模型引擎支持 MTP 推理,并且 MTP 更容易与其他功能兼容,如 CUDA graph 和重叠调度器等。启用 CUDA graph 后,验证和 draft 阶段均可在同一个 graph 中运行,大幅降低了 CPU 开销。
MTP 模块
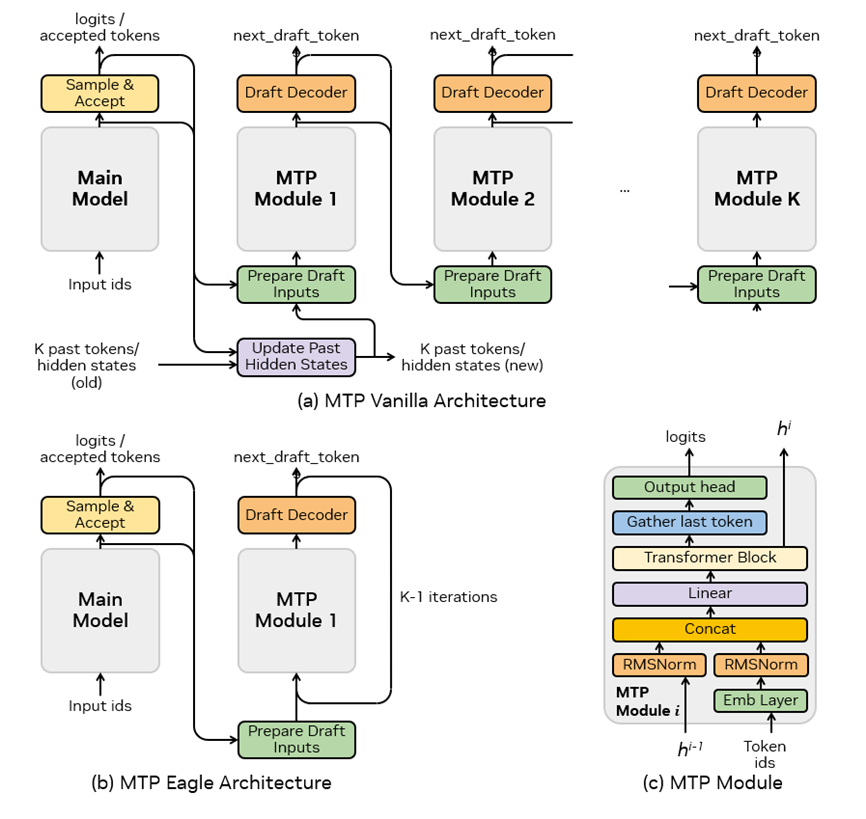
图 5. MTP 模型架构
图 5 介绍了 MTP Vanilla、MTP Eagle 的基本模型架构以及基本 MTP 模块设计。由于 MTP Vanilla 需要 K 个输入 token,若接受的 token 数量少于输入 token 数量(即 j
MTP 模块遵循了 DeepSeek-V3 中的设计,其中嵌入层和输出头与主模型共享,这可以减少 GPU 显存消耗。
支持 MTP 的注意力机制
注意力机制也是支持 MTP 推理的重要组成部分,变化主要体现在生成阶段的注意力内核上。在普通请求情况下,生成阶段仅有一个输入 token,但在 MTP 情况下,将有 K+1 个输入 token。由于 MTP 按顺序预测额外的 token,预测的候选 token 会被链式连接,尽管我们有 MTP Eagle 路径,但目前只支持基于链式的 MTP Eagle。因此,一个因果掩码即可满足注意力内核对 MTP 的支持需求。在我们的实现方式中,TensorRT-LLM 将在 Hopper GPU 上使用FP8 FlashMLA生成内核,在 Blackwell 上使用 TensorRT-LLM 定制注意力内核来实现更高的性能。
如何运行带有 MTP 功能的 DeepSeek 模型
如要运行带有 MTP 功能的 DeepSeek-V3 / R1 模型,请使用 examples/llm-api/quickstart_advanced.py 并添加以下选项:
如要在有 MTP 功能的情况下进行最低延迟性能基准测试,请按照本文档准备数据集,然后按照以下步骤操作:
MTP 优化:宽松接受
DeepSeek-R1 是一种先输出一些思考 token,然后为用户提供实际输出的推理模型。其思考过程通常会消耗大量 token,而思考过程的输出质量对最终答案的影响有限,因此我们希望采用一种更积极的接受策略——宽松接受以加快思考解码阶段的速度,该策略将权衡加速幅度与输出质量。从实验结果来看,宽松接受对输出质量的影响不大。
宽松接受
图 6. 使用 MTP nextn=4 和 top-3 的宽松接受示例。
如图 1 所示,在之前的验证和接受过程中,我们使用 top-1 从主模型的 logits 中采样以获取“预期” token,此时仅有一个选项与候选 token 进行比较,我们称之为“严格接受”。
至于宽松接受,我们首先从 logits 中采样 top-N 个 token,将有更多候选 token 与输入的候选 token 进行比较。为确保接受的 token 尽可能准确,我们还引入了一个概率阈值 delta,我们可通过对 logits 应用 softmax 函数获得 token 概率。在获得前 N 个候选 token 后,我们会移除概率小于(前 1 个概率 - delta)的 token。如此一来,我们可获得多个候选 token,且所有候选 token 的概率均较高。随后,我们可以将输入候选 token 与这些候选 token 进行比较,若其中一个匹配,即可接受该候选 token,从而提高接受率。图 6 比较了严格接受与宽松接受。
需注意,宽松接受仅在思考阶段使用,而严格接受仍在非思考阶段使用。目前宽松接受仅支持 DeepSeek-R1 模型。
如何运行使用宽松接受策略的
DeepSeek-R1 模型
如要运行使用 MTP 宽松接受的 DeepSeek-R1 模型,请使用 examples/llm-api/quickstart_advanced.py 并添加以下选项:
如要在使用 MTP 宽松接受策略的情况下进行最低延迟性能基准测试,请按照本文档准备数据集,然后按照以下步骤操作:
评估
通过 MTP 投机采样实现加速
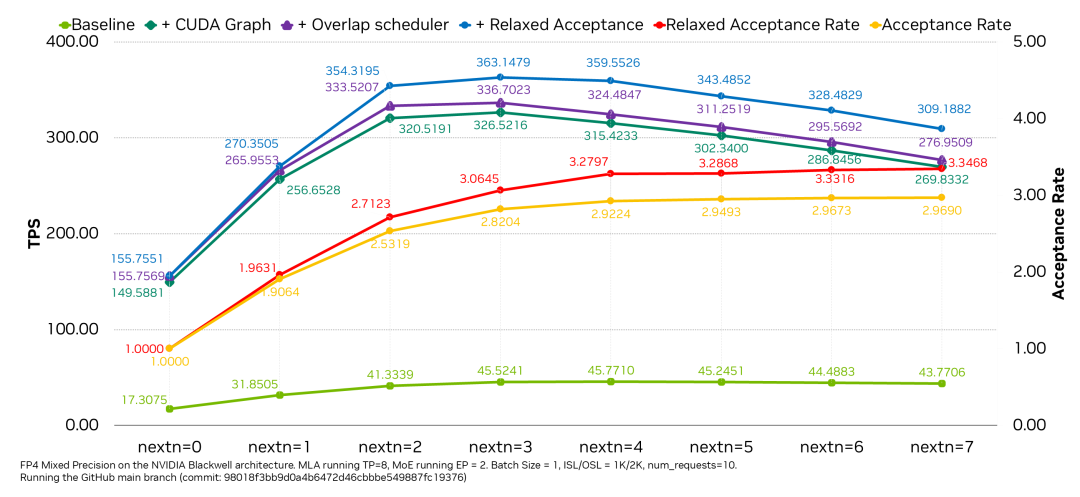
图 7. DeepSeek-R1-FP4 671B 在不同 MTP next-n 设置下的最低延迟性能
我们在 GPU 上测试了 DeepSeek-R1-FP4 模型在不同 MTP next-n 设置下的最低延迟 (batch size=1) 性能。测试中设置 MLA TP=8,MoE EP=2,总共使用 10 个输入请求进行测试,输入序列长度和输出序列长度分别为 1K 和 2K。从图 7 可以看出,在 8 个 GPU 上 MTP=3 可帮助实现最佳的最低延迟性能,与基线 nextn=0 相比提速 2.16 倍。而借助宽松接受策略可进一步减少最低延迟,提速 2.33 倍。我们还评估了 CUDA graph 和重叠调度器的优势。在此类最低延迟场景中,CUDA graph 可实现平均提速 7.22 倍,而重叠调度器则使延迟平均提速 1.03 倍。
使用宽松接受策略时的准确性研究
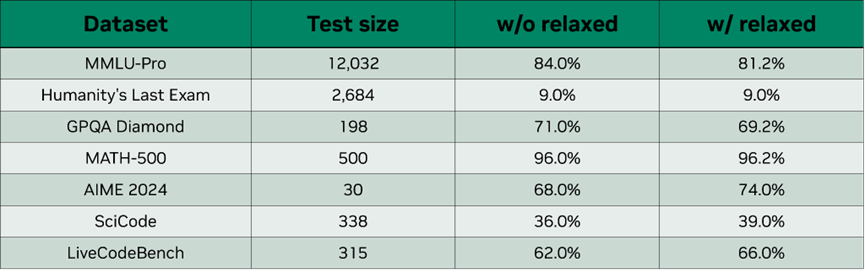
图 8. 使用宽松接受策略时的消融结果,MTP nextn=3、top-10 和 delta=0.6。
我们在不同数据集上验证了宽松接受。图 8 是 DeepSeek-R1-FP4 模型使用宽松接受策略时的消融结果,与严格接受相比,宽松接受对输出质量的影响不大,精度略微下降,个别数据集上还达到了更高的精度。
工作展望
树式投机采样支持
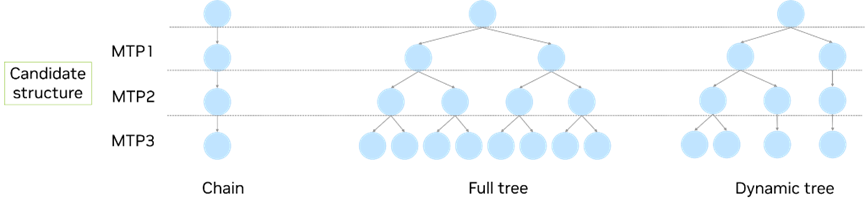
图 9. 链式与树式投机采样技术的比较
TensorRT-LLM PyTorch 后端目前仅支持 MTP Vanilla 和 MTP Eagle 等基于链式的投机采样。为了提高接受率,Eagle2 和 Eagle3 等此前的先进方法广泛采用树式投机采样技术,TensorRT-LLM 中的 MTP 也可扩展以支持树式投机采样技术。图 9 比较了链式方法与树式方法,无论是全树式还是动态树式方法均有助于扩展候选组合,从而提供更多候选 token 供选择。
Eagle3 支持
Eagle3 同样是一项重要的技术。Eagle3 论文的研究结果表明,使用不同层级的隐藏状态预测候选 token 可显著提高接受率。由于 TensorRT-LLM 已支持 Eagle-3,未来我们还计划训练一个 Eagle3 head,结合 DeepSeek-V3 / R1+Eagle3 以实现更好的加速。
致谢
支持和优化 TensorRT-LLM 中的 MTP 是一项了不起的跨团队合作成果。我们谨向所有为此做出贡献的人士致以诚挚感谢,该项目涉及多个技术层面的系统与算法协同设计方法,包括内核优化、运行时增强、算法改进以及性能测量与分析等。特别感谢 DeepSeek 团队开发了这套 MTP 方法,为本文奠定了基础。
作者
张国铭
NVIDIA 性能架构师,目前主要从事大模型推理优化。
李繁荣
NVIDIA Compute Arch 部门高级架构师,目前主要从事大模型推理优化。
cd examples/llm-api
python quickstart_advanced.py--model_dir
YOUR_DATA_PATH=
cd examples/llm-api
python quickstart_advanced.py--model_dir
YOUR_DATA_PATH=
-
NVIDIA
+关注
关注
14文章
5384浏览量
107049 -
模型
+关注
关注
1文章
3572浏览量
50885 -
LLM
+关注
关注
1文章
333浏览量
979 -
DeepSeek
+关注
关注
2文章
811浏览量
2079
原文标题:DeepSeek R1 MTP 在 TensorRT-LLM 中的实现与优化
文章出处:【微信号:NVIDIA-Enterprise,微信公众号:NVIDIA英伟达企业解决方案】欢迎添加关注!文章转载请注明出处。
发布评论请先 登录
NVIDIA Blackwell GPU优化DeepSeek-R1性能 打破DeepSeek-R1在最小延迟场景中的性能纪录

使用NVIDIA Triton和TensorRT-LLM部署TTS应用的最佳实践

如何在魔搭社区使用TensorRT-LLM加速优化Qwen3系列模型推理部署
如何在NVIDIA Blackwell GPU上优化DeepSeek R1吞吐量
TensorRT-LLM中的分离式服务

了解DeepSeek-V3 和 DeepSeek-R1两个大模型的不同定位和应用选择
现已公开发布!欢迎使用 NVIDIA TensorRT-LLM 优化大语言模型推理

魔搭社区借助NVIDIA TensorRT-LLM提升LLM推理效率
TensorRT-LLM低精度推理优化

NVIDIA TensorRT-LLM Roadmap现已在GitHub上公开发布

解锁NVIDIA TensorRT-LLM的卓越性能
在NVIDIA TensorRT-LLM中启用ReDrafter的一些变化

云天励飞上线DeepSeek R1系列模型






 工商网监
工商网监
评论